The Plugin Pipeline: How LLM Security Middleware Should Actually Work
Most security middleware is monolithic. One rule engine. One processing unit. One failure domain. When the rule engine is slow, everything slows. When it crashes, everything stops. When a new threat category emerges, the entire engine needs to be modified, tested, and redeployed.
This is the wrong model for LLM security, and the reason comes down to a fundamental mismatch between how monolithic security tools work and what LLM traffic actually requires.
The problem with a single inspection layer
Traditional API security works on a simple premise: evaluate the request against a ruleset, allow or deny. The ruleset is monolithic — all rules run in the same context, with the same data, at the same point in the request lifecycle.
LLM traffic breaks this in three ways.
First, the inspection requirement changes depending on where you are in the request lifecycle. A secret detection rule that blocks an AWS access key needs to run before the firewall adds overhead, before PII redaction, and certainly before any LLM call is made. A hallucination detection rule, by definition, can only run after the LLM has generated a response. Running both in the same evaluation pass is architecturally incoherent — one of them will always be in the wrong place.
Second, the consequence of a false positive varies by category. Blocking a legitimate message because a secret detection rule fired is a recoverable annoyance. Blocking a message because a response quality check fired against input that hasn't been generated yet is a logic error. The system needs to know when each check is appropriate, not just whether a check should run.
Third, the failure surface of a monolithic engine is the entire engine. A bug in one rule crashes the pipeline. A slow regex degrades every request. A category of rules that needs to be updated forces a full redeploy.
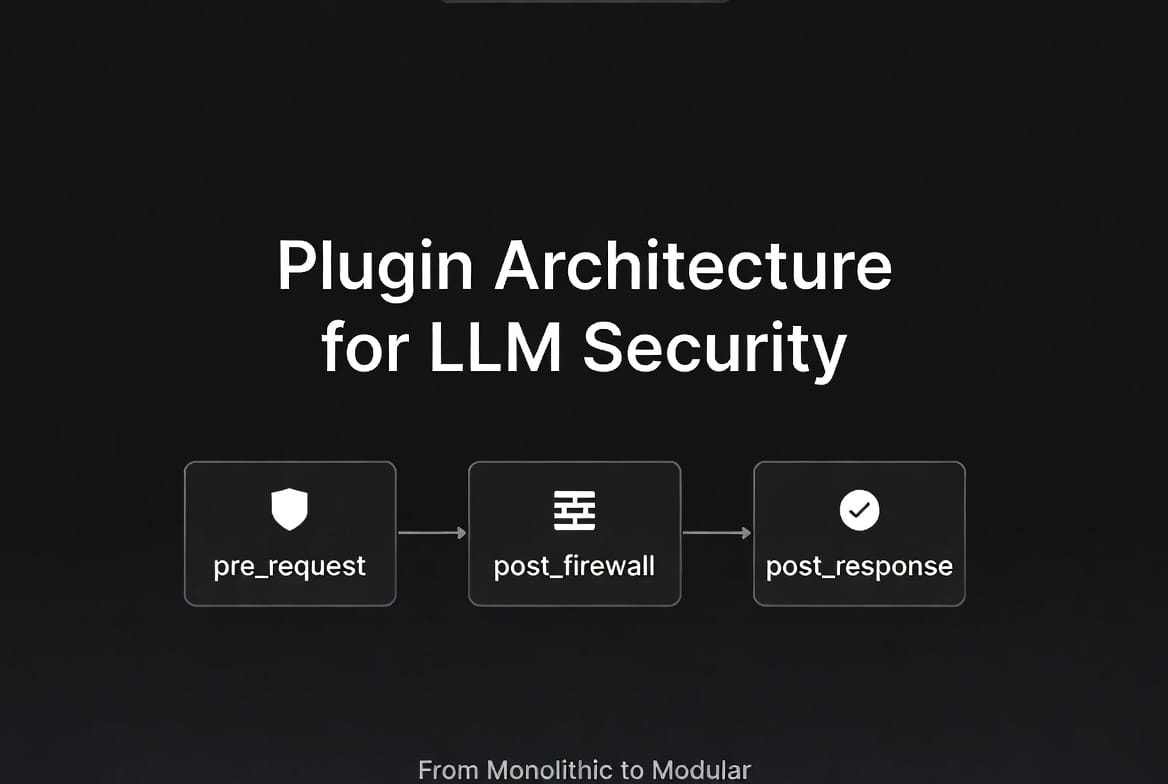
A hook-based architecture
The correct model separates inspection into three distinct lifecycle points, each with a clearly defined contract about what data is available and what the plugin can do with it.
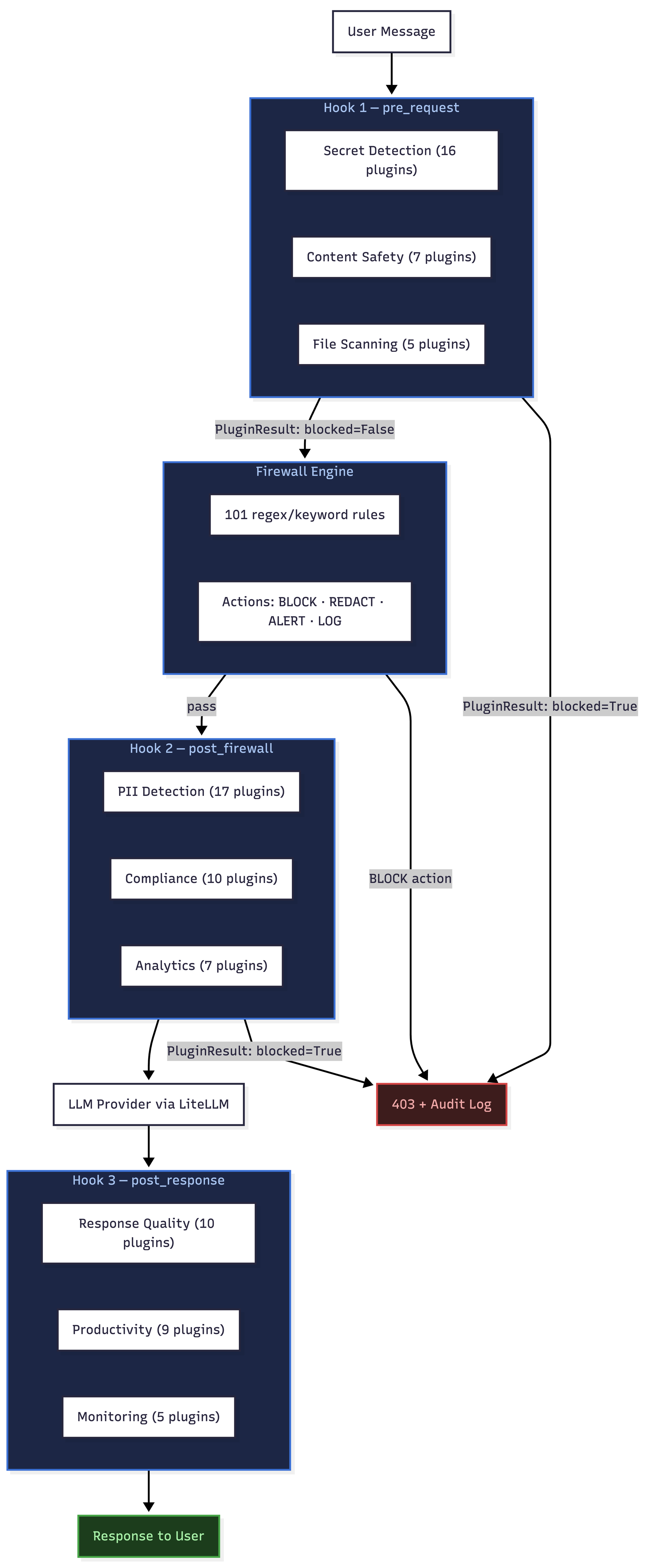
pre_request runs on the raw user message before any other processing. Plugins at this hook have access to the original unmodified input. They can block or modify the message. Secret detection belongs here — if a user pastes an AWS access key, the message should be stopped immediately, before the firewall adds latency, before PII redaction runs, before any data touches the LLM call path.
post_firewall runs after the firewall has evaluated and acted on the message, but before the request is forwarded to the LLM provider. Plugins at this hook receive the firewall-processed content. PII detection and compliance checking belong here — by this point, obvious attacks have already been handled, and the remaining content can be evaluated for more nuanced data protection requirements.
post_response runs after the LLM has generated a response. Plugins at this hook see the model's output. Response quality analysis, hallucination flagging, and productivity enrichment belong here — they operate on content that didn't exist until the model generated it.
Each hook has a clearly defined contract:
class PluginResult:
blocked: bool = False
block_reason: str = ""
modified_message: str = ""
flags: dict = field(default_factory=dict)post_response plugins cannot block — the response has already been generated. pre_request and post_firewall plugins can block, modify the message, or pass flags to downstream plugins. The contract is enforced at the type level.
Plugin categories by hook position
The decision of which hook a plugin belongs to is not arbitrary. It follows from what data the plugin needs and what it's allowed to do.

Secret detection runs at pre_request because secrets should never reach the firewall evaluation loop, let alone the LLM. The 16 secret detection plugins cover AWS, GCP, Azure, GitHub, JWT, Stripe, Slack, SSH keys, .env file content, and database connection strings. Each one fires before any other processing occurs.
PII detection runs at post_firewall because by that point the firewall has already handled structural attacks, and the remaining content can be evaluated for personal data that requires redaction rather than blocking. The 17 PII plugins cover email addresses, phone numbers in 20+ international formats, IBANs with ISO 13616 checksum validation, credit cards with Luhn verification, passport numbers, biometric data references, and dates of birth in context.
Response quality runs at post_response because it operates on generated content. There is no hallucination to detect until the model has hallucinated something.
Isolation as a reliability property
The failure mode of a monolithic security engine is total — one bad rule takes down the pipeline. The failure mode of an isolated plugin is local.
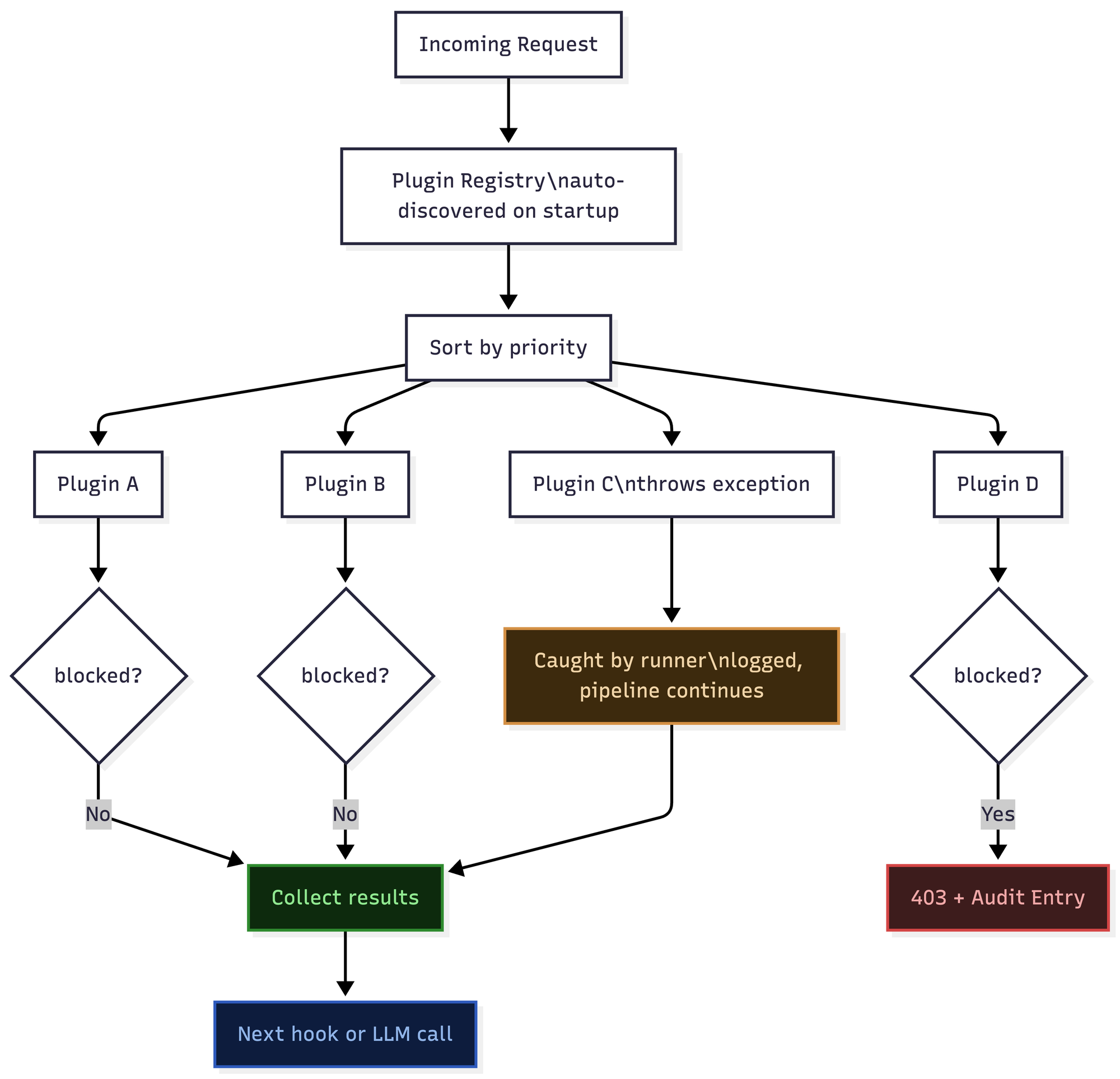
Each plugin runs in its own execution context. If a plugin throws an exception, the runner catches it, logs it with the plugin name and error details, increments the plugin's error counter, and continues to the next plugin. The pipeline does not halt. The request does not fail.
This is not a minor implementation detail. It means that a regex that catastrophically backtraces on pathological input, a plugin that makes a network call and times out, or a plugin with a logic error in an edge case — none of these stop other plugins from running. The audit trail records what happened. The admin panel shows which plugins are erroring and how frequently. The system degrades gracefully.
This property is only achievable with per-plugin isolation. A monolithic engine cannot have it.
Auto-discovery and the operational implication
Plugins are auto-discovered from the gateway/plugins/ directory on startup. Adding a new plugin requires one Python file that extends BasePlugin. No configuration changes. No registry updates. No deployment pipeline modification beyond including the file.
class Plugin(BasePlugin):
@property
def name(self) -> str:
return "my-custom-plugin"
@property
def hooks(self) -> list[str]:
return ["post_firewall"]
async def on_post_firewall(self, ctx: PluginContext) -> PluginResult:
if "confidential" in ctx.message.lower():
return PluginResult(blocked=True, block_reason="Contains confidential data")
return PluginResult()Drop it in the directory. Restart. It runs.
Each of the 101 plugins ships with built-in test cases — 1,193 in total — executable directly from the admin panel. The test runner evaluates each plugin against its defined true positive and false positive cases and reports pass/fail inline. An admin can verify that a plugin is working correctly before enabling it in the live pipeline.
Why this matters at the architecture level
The plugin system is not a feature. It is the mechanism by which security coverage is extended without modifying the core request pipeline.
When a new threat category emerges — a novel prompt injection technique, a new PII format, a compliance requirement specific to a jurisdiction — the response is a new plugin file, not a patch to the firewall engine. The plugin can be tested in isolation, enabled per-deployment, and disabled without downtime if it generates false positives.
This is the difference between a security product and a security platform. A product has a fixed ruleset. A platform has an extensible execution model.
The 101 plugins Klyvex ships with are a starting point. The architecture is the capability.
Klyo is the Enterprise AI Security Gateway. The plugin pipeline, firewall engine, and stateful session inspection are built and running in production.