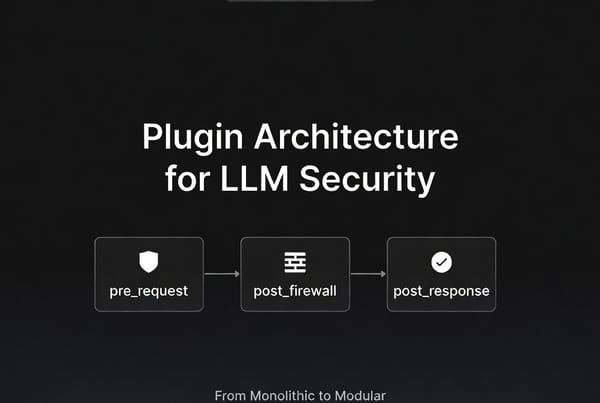
Why existing API gateways fail for LLM traffic
API gateways are not new. Kong, AWS API Gateway, Apigee, NGINX — the category is mature, well-understood, and battle-tested at scale. So when enterprises begin routing LLM traffic, the instinct is obvious: drop it behind the existing gateway, add a rate limit, call it a day.
That instinct is wrong. And the consequences are not theoretical.
The fundamental mismatch
Classical API gateways were designed around a core assumption: requests and responses are structured, bounded, and semantically opaque. The gateway does not need to understand what is inside a request. It needs to know where to route it, whether the caller is authenticated, whether rate limits are respected, and whether the response arrived. The payload is irrelevant to the gateway's job.
LLM traffic breaks every one of these assumptions.
A prompt is not a structured payload. It is natural language — and natural language carries intent, context, and meaning that cannot be extracted by inspecting HTTP headers or JSON field names. The difference between a legitimate request and a prompt injection attack is not structural. It is semantic. A gateway that cannot read meaning cannot defend against attacks that operate through meaning.
Five failure modes
1. Authentication solves the wrong problem
API gateway authentication — API keys, JWT, OAuth — answers the question: who is calling? In LLM environments, the more dangerous question is what are they saying? A fully authenticated, authorized enterprise user can still exfiltrate confidential data by feeding it into a prompt. Identity verification and content inspection are orthogonal concerns. Gateways handle the first. They are structurally blind to the second.
2. Rate limiting is the wrong unit of control
Traditional rate limiting operates on requests per second, requests per minute, or monthly quota. For LLM traffic, the meaningful unit is tokens — and token consumption is wildly variable. A single malicious prompt can consume more tokens than ten thousand normal requests while also encoding an exfiltration attempt inside the generation. Request-count rate limits provide a false sense of cost control and zero protection against semantic abuse.
3. Request/response inspection does not extend to streaming
Modern LLM APIs stream responses as server-sent events. Classical gateways, even those with payload inspection capabilities, were not built to inspect a streaming response body in real time while it is being generated. The response arrives incrementally. A compliant-looking first token does not mean the subsequent 2,000 tokens will not contain redacted data reconstructed through multi-turn probing. You cannot inspect what has not yet arrived.
4. Schema validation is meaningless against natural language
API gateways can validate that a request conforms to an expected schema — correct fields, correct types, correct structure. Against LLM traffic, schema validation confirms that the messages array is well-formed and that model is a valid string. It says nothing about whether the content of those messages constitutes a jailbreak, a prompt injection, a social engineering attempt, or a data exfiltration payload. The attack surface is inside the string. Schema validation stops at the quotes.
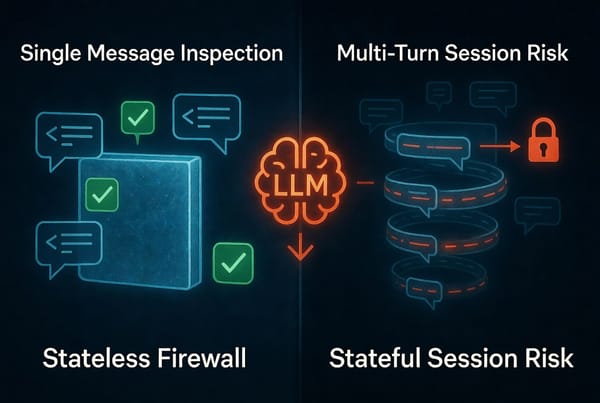
5. No awareness of conversation context
LLM attacks are frequently multi-turn. A single message, examined in isolation, may appear entirely benign. The attack is assembled across multiple exchanges — each individually passing all gateway checks, collectively achieving a jailbreak or bypass. Classical gateways process requests atomically. They have no model of conversation state. A gateway that cannot see the thread cannot detect the pattern.
What is actually required
Defending LLM traffic demands a different class of inspection: semantic, stateful, and content-aware.
Real-time PII detection requires NER-based entity extraction — not regex. Regex catches formats; transformers catch meaning. A custom DeBERTa model fine-tuned on prompt injection patterns can classify adversarial intent before the request reaches the LLM. Redaction pipelines must operate at the token level, not the field level, and must be configurable per data category.
Stateful inspection means maintaining conversation context across turns — not just validating the current request in isolation. Detecting a multi-turn jailbreak requires memory of what was said before. That is not a feature classical gateways were designed to provide.
Token-aware rate limiting means tracking actual consumption at the model level, per user, per group, with configurable ceilings on prompt tokens, completion tokens, and total spend — enforced before the request is forwarded, not reconciled after the bill arrives.
The conclusion enterprises are slow to accept
Existing API gateways are the right tool for API traffic. They are the wrong tool for LLM traffic. The difference is not a matter of configuration. It is architectural. Retrofitting semantic inspection onto a transport-layer tool is the wrong approach — it produces fragile, incomplete coverage with high maintenance burden and low actual security.
LLM traffic needs a gateway built for LLM traffic. One that understands what is being said, not just who is saying it and how often.
That is the problem Klyo was built to solve.
Klyo is the Enterprise AI Security Gateway — real-time PII redaction, prompt injection classification, stateful conversation inspection, and token-aware cost controls.